
Anforderungen
Linux
- 64-Bit (Kernel 3.2+, glibc 2.17+)
- Möglicherweise müssen Sie die folgenden Bibliotheken über den Paketmanager Ihrer Distribution installieren:
libgl1 libmagic1. Auf einem Debian- oder Ubuntu-System können Sie dies mitsudo apt install libgl1 libmagic1tun.Windows
- 64-Bit (Windows 10+, Windows Server 2016+)
Installation
- Laden Sie die Version für Ihre Plattform von https://learn2rag.de/download herunter.
- Extrahieren Sie das Archiv.
- Führen Sie die Datei namens
startaus.
🛈 Beim ersten Start werden die Python-Umgebung und die Abhängigkeiten vorbereitet, was einige Zeit in Anspruch nehmen kann.
Konfiguration
Die Konfiguration der Learn2RAG Software ist als Weboberfläche gestaltet und kann über den Browser geöffnet werden. Dies sollte nach Ausführung des Start-Befehls automatisch geschehen. Falls dies nicht geschieht finden Sie in der Ausgabe des Start-Befehls die URL, die Sie mit ihrem Browser öffnen können, um die Benutzeroberfläche zur Konfiguration zu öffnen.
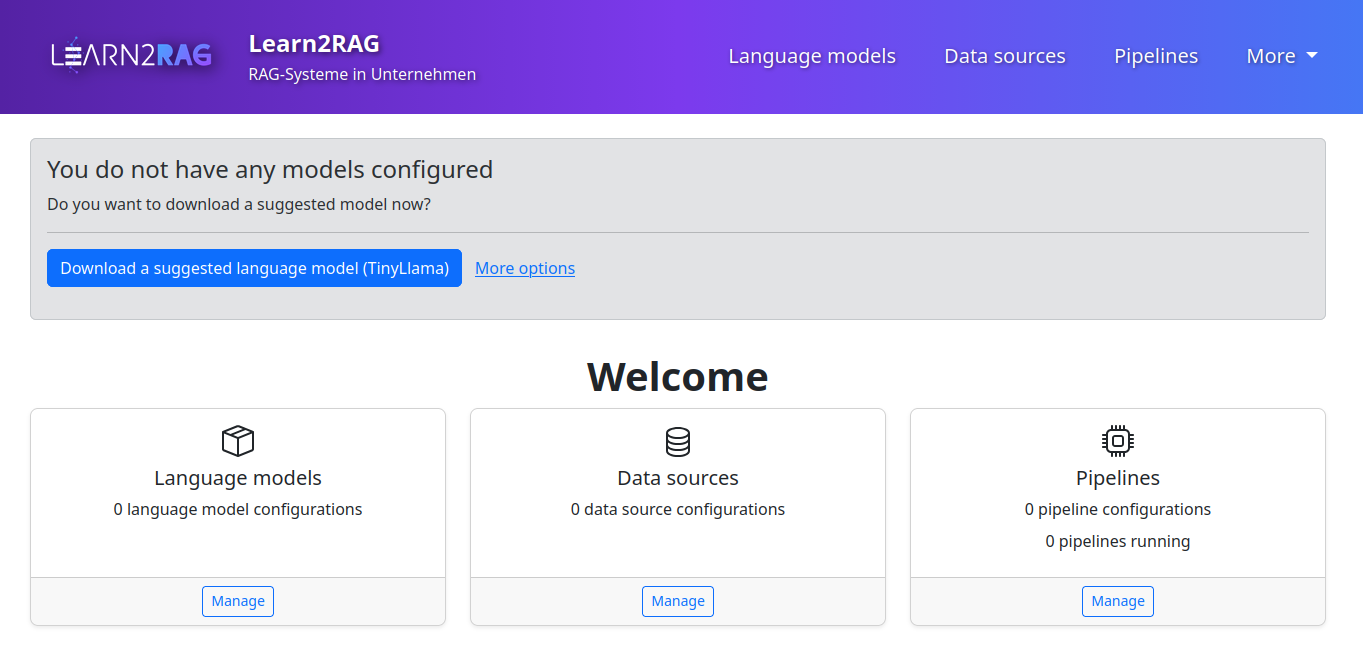
Die Oberfläche des Konfigurators ist in 3 Bereiche eingeteilt: Sprachmodelle, Datenquellen, und Pipelines. Zusätzlich wird beim ersten Starten ein Assistent im oberen Bereich angezeigt, der bei der Erstellung einer ersten RAG Pipeline unterstützt. Diese Assistent und die 3 einzelnen Bereich werden im folgenden näher betrachtet.
Learn2RAG beinhaltet englische und deutsche Lokalisierungen der Benutzeroberfläche. Die Lokalisierung wird gemäß den Einstellungen Ihres Webbrowsers ausgewählt. Weitere Details finden Sie in der Dokumentation Ihres Webbrowsers.
Assistent für den ersten Start
Beim ersten Start, bevor Sie Konfigurationen erstellt haben, wird ein Assistent im oberen Bereich der Seite angezeigt. Dieser hilft Ihnen dabei in wenigen Schritten eine einfache RAG Pipeline zu erstellen. Folgen Sie einfach den vorgegebenen Schritten, um eine grundlegende Beispielkonfiguration einzurichten.
Sprachmodelle
Herunterladbare Sprachmodelle
Learn2RAG kann ein Sprachmodell herunterladen und bereitstellen. Dies geschieht mit Ollama, das automatisch gestartet wird.
Eine kurze Liste empfohlener Sprachmodelle zum Herunterladen wird für einen schnellen Start bereitgestellt. Sie können aber auch jedes andere von Ollama unterstützte Modell auswählen. Eine Übersicht über verfügbare Modelle finden Sie unter: https://ollama.com/library.
🛈 Beachten Sie bitte, dass einige Modelle hohe Anforderungen an die zur Verfügung gestellt Hardware haben können.
Externe Sprachmodelle
Ein externes (lokales oder Remote-) Sprachmodell kann verwendet werden, wenn es über eine OpenAI- oder Ollama-kompatible API verfügbar ist. Sie benötigen eine API-URL und (falls erforderlich) ein Zugriffstoken.
OpenAI’s ChatGPT
- API-Typ
- ChatOpenAI API-URL
- (leer lassen) Zugriffstoken
<Ihr Token>Sprachmodellgpt-4ooder ein anderes OpenAI ModellDatenquellen
In diesem Untermenü werden existierende Datenquellen aufgeführt und es können neue Quellen konfiguriert werden. Dabei hat eine Datenquelle grundsätzlich einen Namen, den Sie frei wählen können, um später die Quelle auswählen zu können.
Auf dieser Seite werden die Datenquellen lediglich konfiguriert. Das Abrufen der eigentlichen Daten von der Quelle erfolgt in einem späteren Schritt, nachdem eine Pipeline konfiguriert und der Datenimport gestartet wurde.
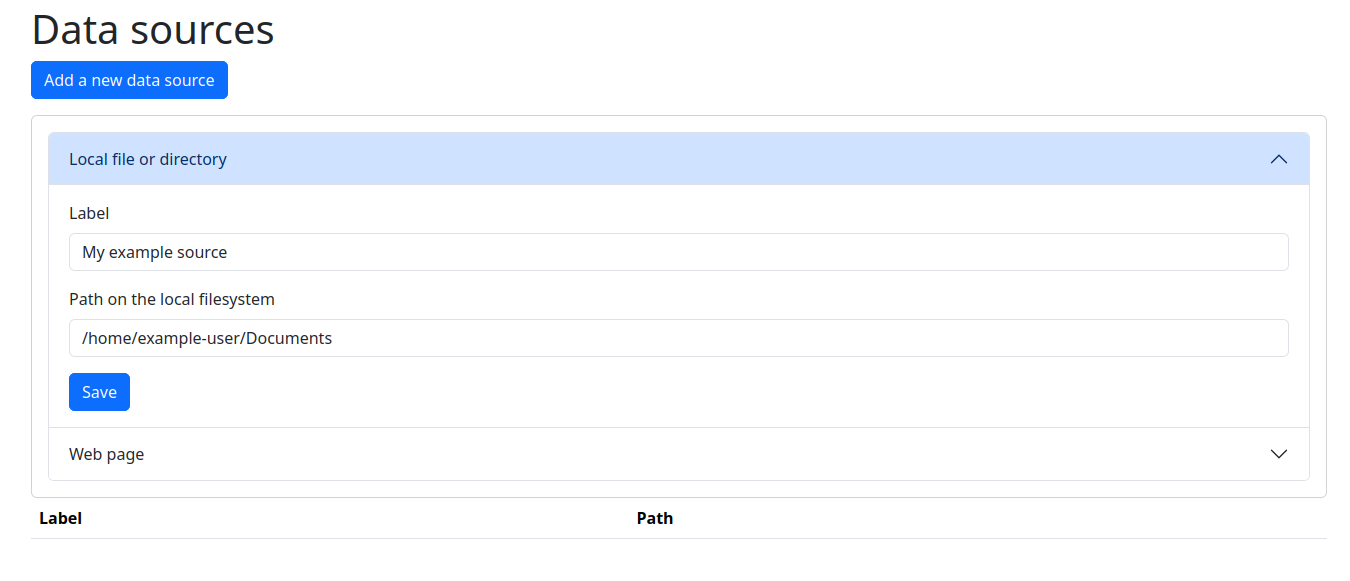
Dateien
Fügen Sie lokale Verzeichnisse (auf demselben PC oder Server, auf dem Learn2RAG ausgeführt wird) hinzu. Zum Beispiel: /home/user/Documents, oder C:\Users\User\Documents.
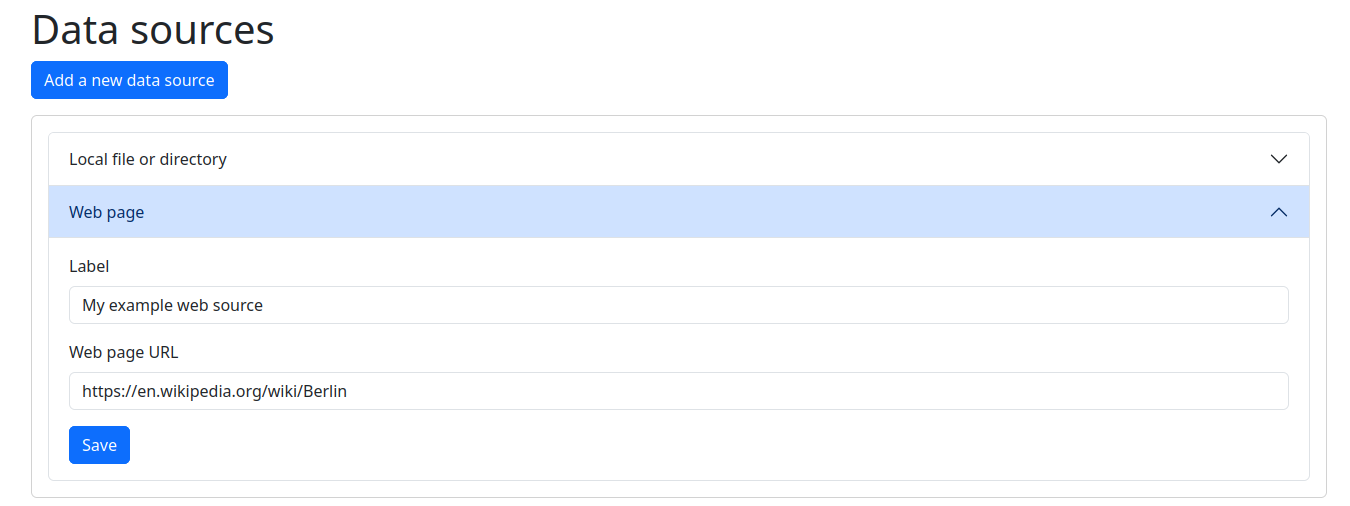
Webseiten
Sie können auch Webseiten als Datenquellen hinzufügen. Zum Beispiel: https://en.wikipedia.org/wiki/Berlin.
Pipelines
Auf dieser Seite können sie eine oder mehrere RAG Pipelines konfigurieren, starten und stoppen.
Minimale Konfiguration
Um eine Pipeline zu erstellen, müssen Sie das Speicherverzeichnis angeben, in dem das System alle zugehörigen Daten speichert, und auswählen, welches konfigurierte Sprachmodelle und welche Datenquellen verwendet werden sollen.
Optionale Konfiguration
Ports
Sie können angeben, welche Ports die Pipeline-Komponenten verwenden sollen. Ansonsten wird die Software automatisch Ports auswählen.
Datenimport
Sie können über eine Checkbox festlegen, ob der Datenimport direkt nach der Konfiguration der Pipeline ausgeführt werden soll. Der Import kann zu jeder Zeit separat gestartet werden (siehe unten).
Verwendung
Nachdem eine Pipeline Pipeline konfiguriert wurde, können Sie diese Pipeline nun steuern. Dabei sollte zunächst der Datenimport gestartet werden, da die Pipeline sonst keinerlei Daten für ihre Arbeit hat.
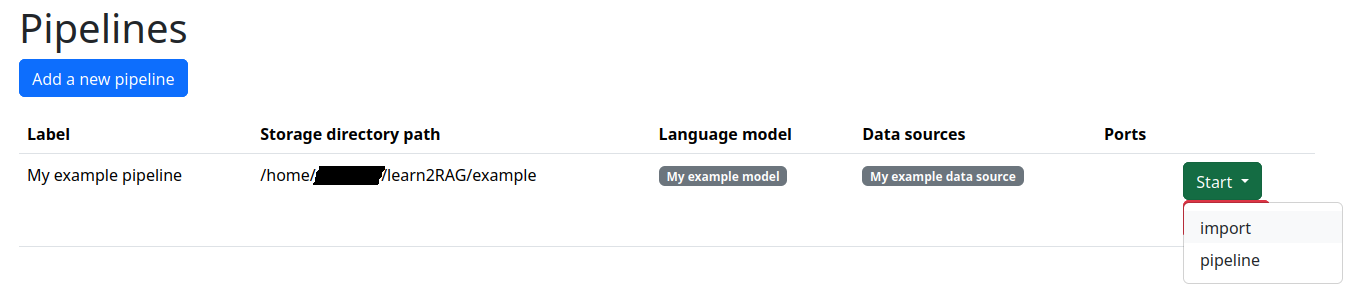
Datenimport
Sobald der Import gestartet wurde verarbeitet die Pipeline alle Daten der ausgewählten Datenquellen. Nach dem Start des Imports müssen Sie warten, bis dieser abgeschlossen ist.
Starten der Pipeline
Durch die Auswahl eine Pipeline zu starten werden die erforderlichen Komponenten der Pipeline erzeugt und gestartet.
Nach dem Start können Sie die Schaltfläche “Open” verwenden, um die Benutzeroberfläche für die RAG Pipeline zu öffnen. Für Details zur Benutzeroberfläche verweisen wir auf das Benutzerhandbuch.
Die Pipeline kann aber auch über eine API in bestehende Software eingebunden werden.
Aktualisierung
- Führen Sie die Datei namens
uninstallaus. - Laden Sie die neue Version der Learn2RAG Software herunter.
- Installieren Sie diese Version wie oben beschrieben.
Deinstallation
Führen Sie die Datei namens uninstall aus. Dadurch werden automatisch erstellte Anwendungsdateien entfernt, Ihre Konfigurationsdaten und heruntergeladenen Modelle jedoch an ihrem Speicherort belassen.
Datenspeicherorte
Linux
$XDG_DATA_HOME/pyapp/(~/.local/share/pyapp/)- Anwendungsdaten
$XDG_DATA_HOME/Learn2RAG/(~/.local/share/Learn2RAG/)- Benutzerdaten
Windows
%LOCALAPPDATA%\pyapp\data\ - Anwendungsdaten
%LOCALAPPDATA%\Learn2RAG\- Benutzerdaten
Erweiterte Konfiguration
Sie können eine Datei config.yml neben der Datei start erstellen, um die Konfigurationsoberfläche anzupassen. Ein Beispiel mit allen unterstützten Optionen: ```yml flask: # Pfad für Anwendungsdaten instance_path: ‘/data/learn2rag’ SUGGESTED_MODELS: local-chat: label: Lokale LLM Konfiguration description: Fügen Sie dort weitere Informationen ein. config: api: ChatOpenAI url: https://example.com/api model: gemma-3-27b-it token: xxx